
声韵听力蒙阴:“能听见却听不懂”,言语识别率比音量更重要。
对于听障人群来说,“能听见却听不懂”士佩戴助听器时最常见的困扰,也直接揭示了;对助听器用户而言,言语识别率的重要性远超过单纯的音量放大。这背后涉及听力损失的特性,助听器的核心功能,以及听障者的真实沟通需求。
1,听力损失的本质;“听不清”比“听不见”更棘手
多数听障患者的问题不是“完全听不到声音”,而是“声音能传到耳朵里,但关键信息丢失了”。
比如,高频听力损失会导致听不清“s,sh,f,t”等辅音,这些辅音音量
通常较弱,但承担了70%以上的语义区分功能。此时,即便通过助听器把音量放大,若无法还原这些辅音的清晰度,大脑依然无法解析语义,结果就是“声音很大,却不知道在说什么”。
再比如,感音神经性听力损失患者的内耳毛细胞受损,不仅对音量敏感,更对“声音的时间分辨率,频率分辨率”下降,他们可能能听到连续的声音,但无法区分叠加在一起的声音(比如在嘈杂环境中,说话声和背景噪音混在一起,就完全听不懂)。这种情况下,单纯放大音量只会比“噪音和语音一起变吵”,反而加剧识别困难。
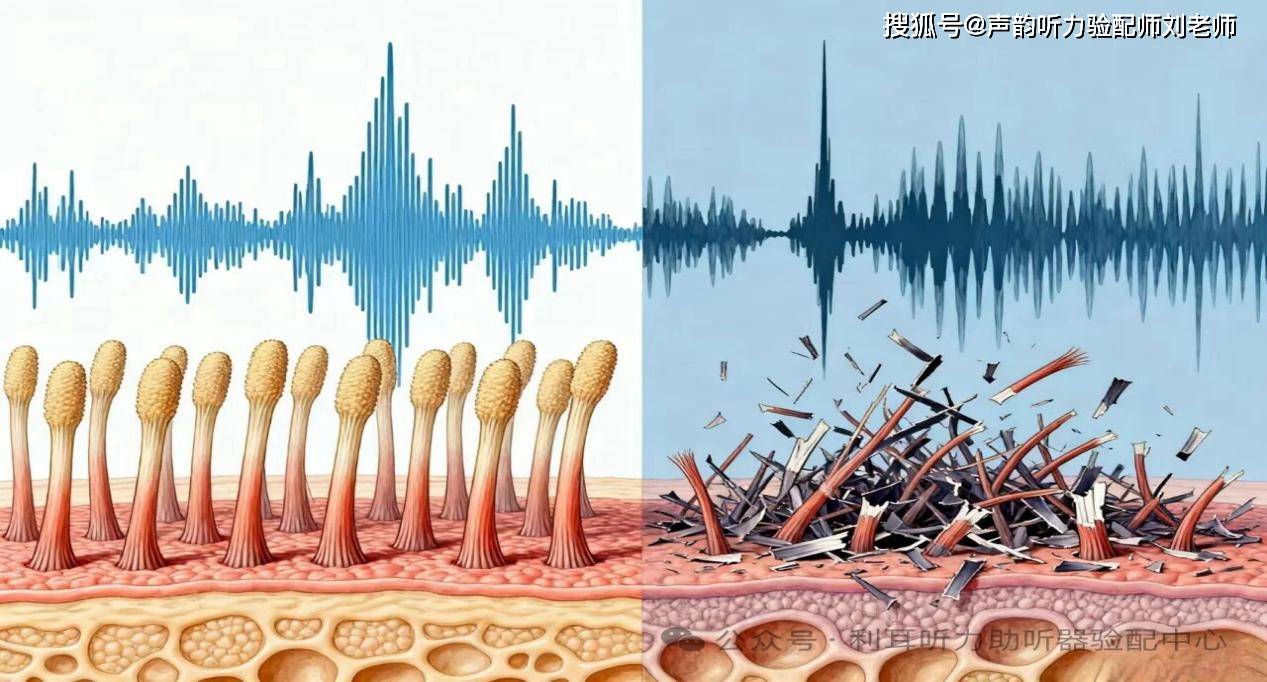
2,助听器的核心价值;“提升分辨率”而非“放大音量”
早期助听器确实以“音量放大”为核心,但现代助听器的技术迭代,本质上都是围绕“提升言语识别率”设计的,因为听障者真正需要的是“听懂。
①降噪技术;通过算法区分语音和噪音,本质是减少噪音对语音识别的干扰,提升“有效语音”的占比。
②方向性麦克风;聚焦前方说话人的声音,消弱后方/侧面的杂音。让用户在多人交谈或嘈杂环境中更易锁定目标语音,解决“声音太多分不清”的问题。
③频率补偿;针对用户的听力损失频段,精准放大“缺失的频率成分”,让辅音,语调等关键信息被补全。
④言语增强算法;通过提取语音中的韵律,节奏特征。强化语音的“辨识度”,帮助大脑更快解析语义,这对听力损失伴随“听觉中枢处理能力下降”的用户尤其重要。
临床数据也显示;助听器的“助听效果”评估核心指标不是“音量提升多少分贝”。而是“言语分辨提升多少”。对助听器用户来说,“音量”只是让声音“被感知”的基础,而“识别率”才是让声音“被理解”的核心,后者直接决定了助听器能否真正解决沟通障碍,让听障者回归正常生活。