
文本分类中词语权重计算改进:新探索助力更精准的文本分类
创始人
2024-12-06 03:25:34
0次
在文本分类领域,词语权重计算的改进具有重要意义。传统的权重计算方法可能存在局限性,例如不能准确反映词语在不同文本语境中的真实影响力。改进后的词语权重计算考虑了更多因素。一方面,融入语义信息,不再单纯依赖词频等简单指标,这有助于区分同词频但语义不同的词语对分类的作用。另一方面,通过结合文档的结构信息,如标题、段落分布等,能够更加精准地确定词语的权重。这种改进使得文本分类的准确性得以提升,让分类系统能够更好地理解文本的内涵,从而为信息检索、内容推荐等众多应用提供更可靠的分类结果。
1概述
随着各种电子形式的文本文档如电子出版物、各种电子文档、电子邮件和万维网等文本数据库等以指数级的速度增长,有效的信息检索、内容管理以及信息过滤等应用也变得越来越重要。文本的自动分类是有效的解决办法之一,并且已经成为一项具实用价值的关键技术。而文本分类所要解决的首要问题就是文本的形式化表示[1]。(参考《建筑中文网》)
在现有的几种文本表示模型中,向量空间模型(VSM)由于具有较强的可计算性和可操作性,得到了广泛了应用并且取得了较好的效果。在该模型中,文档的内容被形式化为多维空间中的一个点,通过向量(vector)的形式给出[2]。因此,向量空间模型文本表示的形式化方法是基于文本处理的各种应用得以实现的基础和前提。基于此,本文针对向量空间模型中经典的词语权重计算方法的不足之处提出了一种结合信息论中信息增益的改进算法,并通过验证了其可行性和有效性。
2传统的TFIDF
传统的特征权重计算主要考虑特征项的频率信息TF以及反文档频率信息IDF[3]。
2.1特征项频率(Term Frequency,TF)
TF是特征项频率,它是指特征项在文档中出现的次数。特征项可以是字、词、短语,也可以是经过语义概念词典进行语义归并或概念词语权重计算方法后的语义单元。不同类别的文档,在某些特征项的出现频率上有很大差异,因此频率信息是文本分类的重要参考之一。它的计算公式为:
2.2反文档频率(Inverse Document Frequency,IDF)
IDF以出现特征词的文本数为参数来构建特征项的权重。其计算方法的出发点是一个特征词文档频数越高,那么其包含的类别信息就越低,也就表示该特征词就越不重要。IDF的计算公式为:
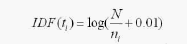
其中N为文档集的总文档数,ni为出现特征项ti的文档数。计算对数时,由于我们计算的权重值是相对的,所以底数可为任意实数,这里用2作为底数计算。
一个有效的分类特征项应该既能体现所属类别的内容,又能将该类别同其它类别区分开来。所以,在实际应用中通常将TF与IDF联合起来使用。公式如下:
由于各类别文本的长度很难一致,各类文本包含的字数、词数可能差别会很大,对词频造成直接影响,因此通常对词频作归一化处理。TFIDF的归一化计算公式如下:
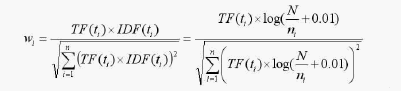
其中wi为第i个特征项在文本中的权重,TF(ti)是特征项ti在文本dj中出现的频数,n表示特征向量的维数。
3传统TFIDF权重计算方法分析
TF.IDF权重计算方法主要从词语的频率TF和词语的反文档频率IDF两个方面进行考虑。计算公式的提出是基于这一假设:对区别文档类别最有意义的词语是在一个文档集合中出现频率足够高,并且在其它文档集合中出现频率足够少的词语。所以,向量空间模型的基础是词语的出现频率和出现文档频率。
这种方法中IDF值的计算是将训练文本集看作一个整体来考虑的,并没有考虑到特征项在类间的分布信息。比如说:如果某一类ci中包含特征项t的文档数为m,而其他类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大时,n也大,根据公式可以得到,IDF的值就越小,则根据TFIDF的计算方法,权重值也会受到影响。但实际上,m大的话,表示t在ci类的文档中频繁出现,就说明t能够很好地代表ci类的文本特征,应该赋予较高的权重。
可以通过一个很小的文档集来说明权重计算方法TFIDF的利弊问题,假设有三个类别c1,c2,c3,每个类别中都各有5篇文档,为了计算方便这里只考虑三个特征项t1,t2,t3。
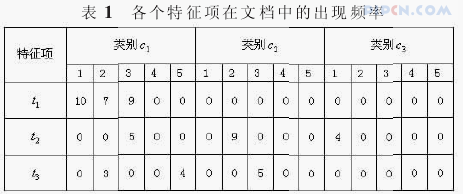
从表1可以看出:t1只有类别c1中出现,所以其分类能力应是最强的;而t2在三个类别中均出现了,所以其分类能力应是最弱的。但是我们来看看他们的IDF的计算结果。如表2所示。
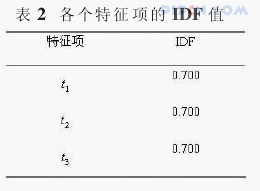
从表中我们可以看到,t1、t2、t3三个特征项的IDF值是相同的,那么其权重大小就完全取决于TF的值,也就是特征项在每个类别中出现的次数,而这显然是很不合理的。出现这种情况的原因,主要是因为计算IDF是基于训练集合中所有文档来考虑的,没有区分特征项在不同类别中的出现的文档数,当然也就无法表示出特征项和类别间的关联性。
为了弥补这一不足,在计算权重时,引入信息增益的概念。
4信息增益(information gain,IG)的引入
4.1信息熵和信息增益
1850年,德国物理学家鲁道夫·克劳修斯首次提出“熵”的概念,用来表示任何一种能量在空间中分布的均匀程度,能量分布得越均匀,熵就越大[4]。1948年,信息论之父C.E.Shannon提出了“信息熵”的概念,解决了对信息的量化度量问题,并且第一次用数学语言阐明了概率与信息冗余度的关系[5]。
信息熵,又称Shannon熵,在随机事件发生以前,它表示结果不确定性的量度;在随机事件发生以后,它表示我们从事件中所得到的信息的量度(信息量)[6]。
信息论量度信息,是把获得的信息看作用来消除不确定性的东西,信息量的大小用被消除的不确定性的多少来表示。假设随机事情X在获得信息y之前的不确定性为H(X),获得信息y之后为H(X/y),信息y中包含的关于事件X的信息量为:
假如信息概率空间为,那么其不确定度可以表示为:
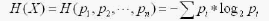
条件熵是H(X/y)获得信息y后X的不确定程度。
信息增益是信息熵的差,表示为:
H(X)表示在获得信息y之前系统的熵。对于文本分类而言,其表示的是一个随机文档落入某个类的概率空间的熵,即类别集合X所能提供的信息量的多少。H(X/y)表示获得y后,此文档落入某个类的概率空间的熵,即观察到y之后所能提供的信息量。这种不确定程度减少的量也就是信息增益,代表y对分类所起到的作用,即它所能提供的分类信息量。
4.2用信息增益来调整权重
我们从信息论的角度出来,把信息增益考虑进了词语在各文档中的分布比例对权重的影响中。将训练文档集看成一个符合某种概率分布的信息源,词语在文本分类中所能提供的信息量(也就是词语在分类中的重要程度)依靠训练文档集的类别信息熵和文档类别中该词语的条件熵之间信息量的增益来确定。并且将这种重要程度反映到了权重计算公式中,提出了如下TF.IDF.IG权重计算公式:
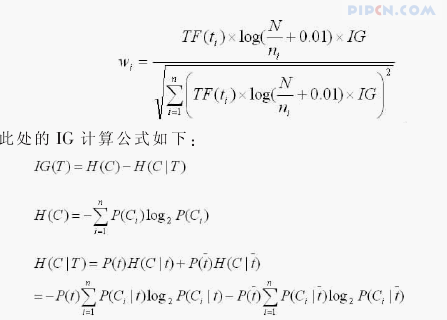
其中,P(Ci)表示类别(Ci)出现的概率,P(t)是特征T出现的概率,用出现过T的档数除以总文档数,表示出现T时类别Ci出现的概率。
还是采用上文第2节的小例子,先计算各词语对于分类的信息增益情况。
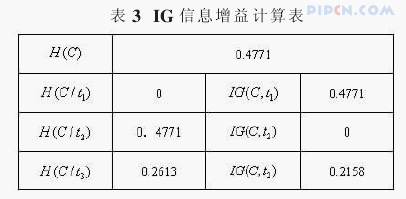
IG的值越高,表示特征项对于分类所能提供的信息量就越多,从表3中可以看出,IG的计算结果与我们主观判断的结果是相同的。t1只在类c1中出现,所以其对于分类的结果应该是最重要的,t3次之,而t2由于是三个类别中均出现过,所以其对于分类的结果是最不重要的,它对于分类的信息增益值也是最小的。再来看看将IG考虑进权重计算公式后,词语的权重,并与传统的权重计算公式的结果相对比。
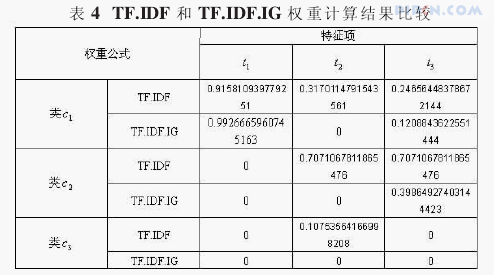
由表4中的权重计算结果可以看到,两种权重计算公式对于t1的分类能力都是给予肯定的。而对于t2,由于它在三个类别中均出现过,传统的TF.IDF的公式没有考虑到类别层次上,所以用传统公式计算时,它的权重是要大于t3的权重的。而在改进的公式中,明显可以看到t2对于三个类别都是没有分类能力的。
从上面的分析中,可以十分清晰地看到改进的TF.IDF.IG公式相对于传统公式的长处,以及其对于分类问题当中特征词权重计算的改善,结果表明这是可行的。
5实验及结果分析
为了进一步验证改进公式的有效性,在实际的分类问题中再次对比两个公式的分类结果。本文选用搜狗实验室提供的中文文本分类语料库中的数据来进行本次实验。
原文网址:http://www.pipcn.com/research/201109/15100.htm
相关内容
热门资讯
以心护心,用坚守传递温暖——董...
心脑血管的健康,关乎每个人的日常生活,关乎每个家庭的幸福安宁。董田林在这一方向上坚守多年,没有惊天动...
如何与暴脾气的躁狂症的家人相处...
近期有人问到,家里的病人一言不合就准备打人怎么办,这是很多人会遇到的实际问题,我觉得以下几点可以供大...
原创 小...
小满是春夏交替的关键节点,雨水增多、湿热弥漫,体内湿气容易堆积,让人困倦乏力、脾胃虚弱、心烦燥热。老...
后日芒种,切记:1不碰,2要勤...
后日芒种,切记:1不碰,2要勤,吃3样,忌1事,为入伏做好准备 后天就是芒种,这是夏天的分水岭!天气...
空腹吃香蕉=减肥?别瞎跟风!正...
有人说,空腹吃香蕉能促进代谢、减少食欲,轻松瘦下来;也有人说,空腹吃香蕉伤肠胃,不仅不减肥,还可能影...
原创 三...
你可能难以置信,在威尼斯电影节的红毯上,那位肩膀缩水、面部凹陷的男人,竟然真的是曾经的巨石强森!那个...
原创 医...
近来关于戒烟之后身体变化的讨论越来越多,尤其是男性群体中长期吸烟的比例不低,很多人对“停烟之后到底会...
原创 玉...
玉米这种食物在日常饮食里其实挺常见的,但很多人对它的认识停留在“粗粮”“填肚子”“偶尔吃一根”的层面...
总决赛前瞻:文班手握邓肯剧本 ...
马刺能站上总决赛舞台,多少算是个意外。 毕竟,在本赛季开始前,谈到西部的争冠强队,人们首先想到都是雷...
喝这种茶一个月瘦5斤?别不信,...
做茶这些年,常有人问:“喝茶是否真的减肥?” 是的,喝茶真能减肥。 这不是小编自己杜撰的,都是有出处...